Read-through: Wasserstein GAN
Last edited February 26, 2017.
I really, really like the Wasserstein GAN paper. I know it’s already gotten a lot of hype, but I feel like it could use more.
I also think the theory in the paper scared off a lot of people, which is a bit of a shame. This is my contribution to make the paper more accessible, while hopefully retaining the thrust of the argument.
Why Is This Paper Important?
There’s a giant firehose of machine learning papers - how do you decide which ones are worth reading closely?
For Wasserstein GAN, it was mostly compelling word of mouth.
- The paper proposes a new GAN training algorithm that works well on the common GAN datasets.
- Said training algorithm is backed up by theory. In deep learning, not all theory-justified papers have good empirical results, but theory-justified papers with good empirical results have really good empirical results. For those papers, it’s very important to understand their theory, because the theory usually explains why they perform so much better.
- I heard that in Wasserstein GAN, you can (and should) train the discriminator to convergence. If true, it would remove needing to balance generator updates with discriminator updates, which feels like one of the big sources of black magic for making GANs train.
- The paper shows a correlation between discriminator loss and perceptual quality. This is actually huge if it holds up well. In my limited GAN experience, one of the big problems is that the loss doesn’t really mean anything, thanks to adversarial training, which makes it hard to judge if models are training or not. Reinforcement learning has a similar problem with its loss functions, but there we at least get mean episode reward. Even a rough quantitative measure of training progress could be good enough to use automated hyperparam optimization tricks, like Bayesian optimization. (See this post and this post for nice introductions to automatic hyperparam tuning.)
Additionally, I buy the argument that GANs have close connections to actor-critic reinforcement learning. (See Pfau & Vinyals 2017.) RL is definitely one of my research interests. Also, GANs are taking over the world; I should probably keep an eye on GAN papers anyways.
At this point, you may want to download the paper yourself, especially if you want more of the theoretical details. To aid anyone who takes me up on this, the section names in this post will match the ones in the paper.
Introduction
The paper begins with background on generative models.
When learning generative models, we assume the data we have comes from some unknown distribution . (The r stands for real.) We want to learn a distribution that approximates , where are the parameters of the distribution.
You can imagine two approaches for doing this.
- Directly learn the probability density function . Meaning, is some differentiable function such that and . We optimize through maximum likelihood estimation.
- Learn a function that transforms an existing distribution into . Here, is some differentiable function, is a common distribution (usually uniform or Gaussian), and .
The paper starts by explaining why the first approach runs into problems.
Given function , the MLE objective is
In the limit, this is equivalent to minimizing the KL-divergence .
Aside: Why Is This True?
Recall that for continuous distributions and , the KL divergence is
In the limit (as ), samples will appear based on the data distribution , so
(Derivations in order: limit of summation turns into integral, flip max to min by negating, add a constant that doesn’t depends on , and apply definition of KL divergence.)
Note that if at an where , the KL divergence goes to . This is bad for the MLE if has low dimensional support, because it’ll be very unlikely that all of lies within that support. If even a single data point lies outside ’s support, the KL divergence will explode.
To deal with this, we can add random noise to when training the MLE. This ensures the distribution is defined everywhere. But now we introduce some error, and empirically people have needed to add a lot of random noise to make models train. That kind of sucks. Additionally, even if we learn a good density , it may be computationally expensive to sample from .
This motivates the latter approach, of learning a (a generator) to transform a known distribution . The other motivation is that it’s very easy to generate samples. Given a trained , simply sample random noise , and evaluate . (The downside of this approach is that we don’t explicitly know what , but in practice this isn’t that important.)
To train (and by extension ), we need a measure of distance between distributions.
(Note: I will use metric, distance function, and divergence interchangeably. I know this isn’t technically accurate. In particular metric and divergence mean different things. I apologize in advance, the three are all heavily conflated in my head.)
Different metrics (different definitions of distance) induce different sets of convergent sequences. We say distance is weaker than distance if every sequence that converges under converges under .
Looping back to generative models, given a distance , we can treat as a loss function. Minimizing with respect to will bring close to . This is principled as long as the mapping is continuous (which will be true if is a neural net).
Different Distances
We know we want to minimize , but how do we define ? This section compares various distances and their properties.
Now, I’ll be honest, my measure theory is pretty awful. And the paper immediately starts talking about compact metric sets, Borel subsets, and so forth. This is admirable from a theory standpoint. However, in machine learning, we’re usually working with functions that are “nice enough” (differentiable almost everywhere), and can therefore ignore many of the precise definitions without destroying the argument too much. As long as we aren’t doing any bullshit like the Cantor set, we’re good.
On to the distances at play.
- The Total Variation (TV) distance is
-
The Kullback-Leibler (KL) divergence is
This isn’t symmetric. The reverse KL divergence is defined as .
-
The Jenson-Shannon (JS) divergence: Let be the mixture distribution . Then
-
Finally, the Earth Mover (EM) or Wasserstein distance: Let be the set of all joint distributions whose marginal distributions are and . Then.
Aside: What’s Up With The Earth Mover Definition?
The EM distance definition is a bit opaque. It took me a while to understand it, but I was very pleased once I did.
First, the intuitive goal of the EM distance. Probability distributions are defined by how much mass they put on each point. Imagine we started with distribution , and wanted to move mass around to change the distribution into . Moving mass by distance costs effort. The earth mover distance is the minimal effort we need to spend.
Why does the infimum over give the minimal effort? You can think of each as a transport plan. To execute the plan, for all move mass from to .
Every strategy for moving weight can be represented this way. But what properties does the plan need to satisfy to transform into ?
- The amount of mass that leaves is . This must equal , the amount of mass originally at .
- The amount of mass that enters is . This must equal , the amount of mass that ends up at .
This shows why the marginals of must be and . For scoring, the effort spent is Computing the infinum of this over all valid gives the earth mover distance.
Now, the paper introduces a simple example to argue why we should care about the Earth-Mover distance.
Consider probability distributions defined over . Let the true data distribution be , with sampled uniformly from . Consider the family of distributions , where , with also sampled from .
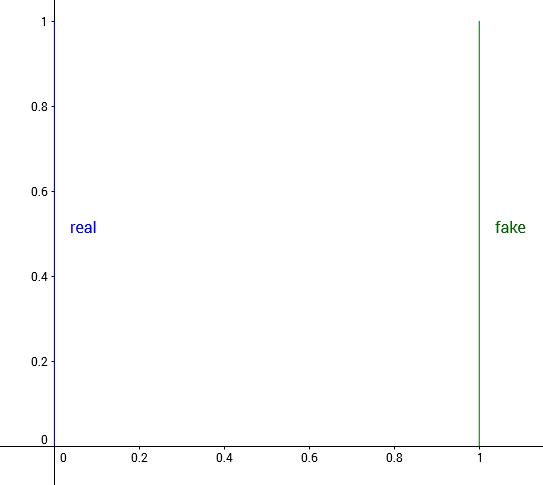
Real and fake distribution when
We’d like our optimization algorithm to learn to move to , As , the distance should decrease. But for many common distance functions, this doesn’t happen.
- Total variation: For any , let . This gives
- KL divergence and reverse KL divergence: Recall that the KL divergence is if there is any point where and . For , this is true at . For , this is true at .
- Jenson-Shannon divergence: Consider the mixture , and now look at just one of the KL terms.
For any where , , so this integral works out to . The same is true of , so the JS divergence is
- Earth Mover distance: Because the two distributions are just translations of one another, the best way transport plan moves mass in a straight line from to . This gives
This example shows that there exist sequences of distributions that don’t converge under the JS, KL, reverse KL, or TV divergence, but which do converge under the EM distance.
This example also shows that for the JS, KL, reverse KL, and TV divergence, there are cases where the gradient is always . This is especially damning from an optimization perspective - any approach that works by taking the gradient will fail in these cases.
Admittedly, this is a contrived example because the supports are disjoint, but the paper points out that when the supports are low dimensional manifolds in high dimensional space, it’s very easy for the intersection to be measure zero, which is enough to give similarly bad results.
This argument is then strengthened by the following theorem.
Let be a fixed distribution. Let be a random variable. Let be a deterministic function parametrized by , and let . Then,
- If is continuous in , so is .
- If is sufficiently nice, then is continuous everywhere, and differentiable almost everywhere.
- Statements 1-2 are false for the Jensen-Shannon divergence and all the KLs.
You’ll need to refer to the paper to see what “sufficiently nice” means, but for our purposes it’s enough to know that it’s satisfied for feedfoward networks that use standard nonlinearites. Thus, out of JS, KL, and Wassertstein distance, only the Wasserstein distance has guarantees of continuity and differentiability, which are both things you really want in a loss function.
The second theorem shows that not only does the Wasserstein distance give better guarantees, it’s also the weakest of the group.
Let be a distribution, and be a sequence of distributions. Then, the following are true about the limit.
- The following statements are equivalent.
- with the total variation distance.
- with the Jensen-Shannon divergence.
- The following statements are equivalent.
- .
- , where represents convergence in distribution for random variables.
- or imply the statements in (1).
- The statements in (1) imply the statements in (2).
Together, this proves that every distribution that converges under the KL, reverse-KL, TV, and JS divergences also converges under the Wasserstein divergence. It also proves that a small earth mover distance corresponds to a small difference in distributions.
Combined, this shows the Wasserstein distance is a compelling loss function for generative models.
Wasserstein GAN
Unfortunately, computing the Wasserstein distance exactly is intractable. Let’s repeat the definition.
The paper now shows how we can compute an approximation of this.
A result from Kantorovich-Rubinstein duality shows is equivalent to
where the supremum is taken over all -Lipschitz functions.
Aside: What Does Lipschitz Mean?
Let and be distance functions on spaces and . A function is -Lipschitz if for all ,
Intuitively, the slope of a -Lipschitz function never exceeds , for a more general definition of slope.
If we replace the supremum over -Lipschitz functions with the supremum over -Lipschitz functions, then the supremum is instead. (This is true because every -Lipschitz function is a -Lipschitz function if you divide it by , and the Wasserstein objective is linear.)
The supremum over -Lipschitz functions is still intractable, but now it’s easier to approximate. Suppose we have a parametrized function family , where are the weights and is the set of all possible weights. Further suppose these functions are all -Lipschitz for some . Then we have
For optimization purposes, we don’t even need to know what is! It’s enough to know that it exists, and that it’s fixed throughout training process. Sure, gradients of will be scaled by an unknown , but they’ll also be scaled by the learning rate , so will get absorbed into the hyperparam tuning.
If contains the true supremum among -Lipschitz functions, this gives the distance exactly. This probably won’t be true. In that case, the approximation’s quality depends on what -Lipschitz functions are missing from .
Now, let’s loop all this back to generative models. We’d like to train to match . Intuitively, given a fixed , we can compute the optimal for the Wasserstein distance. We can then backprop through to get the gradient for .
The training process has now broken into three steps.
- For a fixed , compute an approximation of by training to convergence.
- Once we find the optimal , compute the gradient by sampling several .
- Update , and repeat the process.
There’s one final detail. This entire derivation only works when the function family is -Lipschitz. To guarantee this is true, we use weight clamping. The weights are constrained to lie within , by clipping after every update to .
The full algorithm is below.

Aside: Compare & Contrast: Standard GANs
Let’s compare the WGAN algorithm with the standard GAN algorithm.
-
In GANS, the discriminator maximizes
where we constraint to always be a probabiity .
In WGANs, nothing requires to output a probability. This explains why the authors tend to call the critic instead of the discriminator - it’s not explicitly trying to classify inputs as real or fake.
- The original GAN paper showed that in the limit, the maximum of the discriminator objective above is the Jenson-Shannon divergence, up to scaling and constant factors.
In WGANs, it’s the Wasserstein distance instead.
- Although GANs are formulated as a min max problem, in practice we we never train to convergence. In fact, usually the discriminator is too strong, and we need to alternate gradient updates between and to get reasonable generator updates.
We aren’t updating against the Jenson-Shannon divergence, or even an approximation of the Jenson-Shannon divergence, we’re updating against an objective that kind of aims towards the JS divergence, but doesn’t go all the way. It certainly works, but in light of the points this paper makes about gradients of the JS divergence, it’s a bit surprising it does work.
In contrast, because the Wasserstein distance is differentiable nearly everywhere, we can (and should) train to convergence before each generator update, to get as accurate an estimate of as possible. (The more accurate is, the more accurate the gradient .)
Empirical Results
First, the authors set up a small experiment to showcase the difference between GAN and WGAN. There are two 1D Gaussian distributions, blue for real and green for fake. Train a GAN discriminator and WGAN critic to optimality, then plot their values over the space. The red curve is the GAN discriminator output, and the cyan curve is the WGAN critic output.
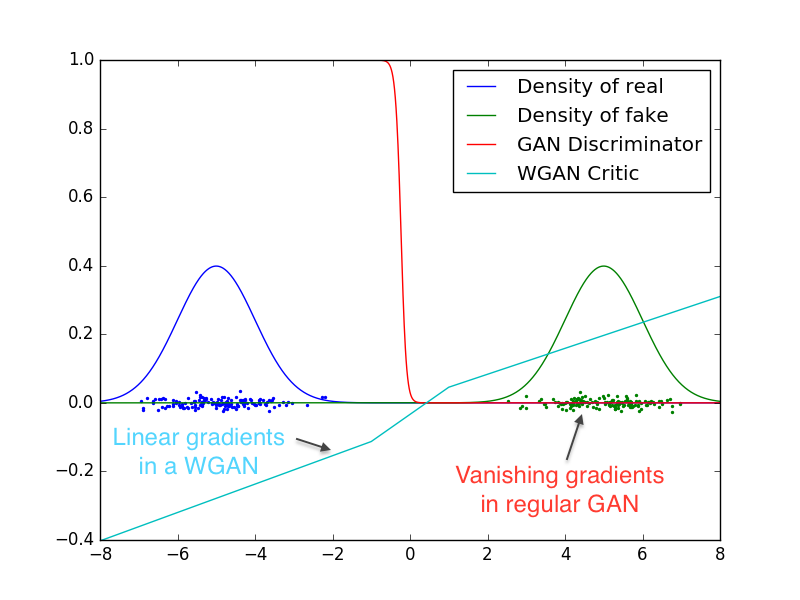
Both identify which distribution is real and which is fake, but the GAN discriminator does so in a way that makes gradients vanish over most of the space. In contrast, the weight clamping in WGAN gives a reasonably nice gradient over everything.
Next, the Wasserstein loss seems to correlate well with image quality. Here, the authors plot the loss curve over time, along with the generated samples.
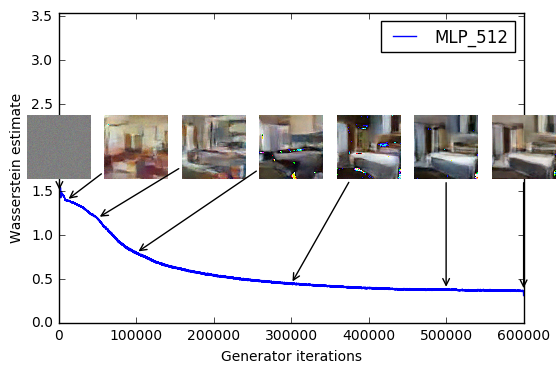
After reading through the paper, this isn’t too surprising. Since we’re training the critic to convergence, these critic’s value should be good approximations of , where is whatever the Lipschitz constant is. As argued before, a low means and are “close” to one another. It would be more surprising if the critic value didn’t correspond to visual similarity.
The image results also look quite good. Compared to the DCGAN baseline on the bedroom dataset, it performs about as well.


Top: WGAN with the same DCGAN architecture. Bottom: DCGAN
If we remove batch norm from the generator, WGAN still generates okay samples, but DCGAN fails completely.


Top: WGAN with DCGAN architecture, no batch norm. Bottom: DCGAN, no batch norm.
Finally, we make the generator a feedforward net instead of a convolutional one. This keeps the number of parameters the same, while removing the inductive bias from convolutional models. The WGAN samples are more detailed, and don’t mode collapse as much as standard GAN. In fact, they report never running into mode collapse at all for WGANs!


Top: WGAN with MLP architecture. Bottom: Standard GAN, same architecture.
Follow-Up Questions
The read-through of the paper ends here. If you’re interested in the Related Work, or the theorem proofs in the Appendix, you’ll need to read the paper.
This is a rich enough paper to have several natural follow-up questions.
The weights in are clamped to . How important is for performance? Based on lurking /r/MachineLearning, the tentative results say that low trains more reliably, but high trains faster when it does work. I imagine it’s because there’s a discrepancy between and , and that discrepancy changes with . There could be interesting work in describing that discrepancy, or in finding ways to bring closer to -Lipschitz functions while still be optimizable.
Given a fixed critic architecture and fixed for clamping, can we quantitatively compare different generators by computing the Wasserstein estimate of both? Again, remember there’s an approximation error from optimizing over instead of , so we may not be able to do much. However, because we fix both the critic architecture and , the hope is that most of the error is some universal error that appears in all distributions. If the approximation error doesn’t change too much between distributions, this would give a way to judge generation quality without relying on Mechanical Turk. (And if the error does change a lot, it would probably be interesting to investigate when that happens.)
The constant depends on both and the model architecture, and therefore we can’t directly compare the critics between models with different architectures. Is there a way to estimate ? Recall the critic objective converges to , so dividing by would normalize the difference between architectures.
(This actually seems pretty straightforward. Take either a random generator or pretrained generator, then train critics from varying architectures and compare their final values. Again, the approximation error could complicate this, but this could be a way to analyze the approximation error itself. Given a few different generators, the change in estimated between different distributions would show how important the distribution is to the approximation error.)
How important is it to train the critic to convergence? A converged critic gives the most accurate gradient, but it takes more time. In settings where that’s impractical, can a simple alternating gradient scheme work?
What ideas from this work are applicable to actor-critic RL? At a first glance, I’m now very interested in investigating the magnitude of the actor gradients. If they tend to be very large or very small, we may have a similar saturation problem, and adding a Lipschitz bound through weight clamping could help.
These ideas apply not just to generative models, but to general distribution matching problems. Are there any low-hanging distribution matching problems that use the Jenson-Shannon or KL divergence instead of the Wasserstein distance? One example of this is the Generative Adversarial Imitation Learning paper. After a decent amount of theory, it derives a GAN-like algorithm for imitation learning. Switching the discriminator to a WGAN approach may give some straightforward wins.